Implementing a RISC-V Hypervisor
2025-05-17
To implement a seamless Linux integration into Starina, I decided to go with a Linux lightweight VM approach similar to WSL2. This means I need to implement a hypervisor that can run Linux.
I had implemented an Intel VT-x based hypervisor before, but this time I wanted to try something different: RISC-V H-extension based hypervisor!
This post is a diary of my journey of writing a RISC-V hypervisor incrementally.
RISC-V H-extension
RISC-V H-extension introduces new CPU modes and some more CSRs (so-called control registers) to implement hardware-assisted virtualization. Its design is similar to Intel VT-x in the sense that both host and guest modes have their own kernel mode and user mode. This design makes it easy to run host OS along with guests, that is, guests behave as normal host processes (e.g. QEMU and Firecracker).
How can I test a hypervisor on macOS?
Unlike Linux KVM-based hypervisors (more specifically, virtual machine monitors), Starina is a new operating system and has been tested on QEMU.
In this case, you typically need to use nested virtualization where the hardware-assisted virtualization is emulated by the host OS. That’s how I did it for Intel VT-x.
Here’s great news: QEMU itself can emulate RISC-V H-extension! You just need to add -cpu rv64,h=true to the QEMU command line. I presume this is thanks to RISC-V’s simplicity and designers’ foresight (and of course QEMU developers’ effort!).
Having a software emulation in QEMU is a key enabler when you’re writing a new operating system from scratch because you can attach GDB to QEMU to debug the OS.
Step 1: Entering the guest
The first thing to do is to enter the guest state. In RISC-V, guest kernel mode is called VS-mode. In RISC-V, you just fill a few CSRs. Specifically, hstatus.SPV should be set to 1 before sret instruction:
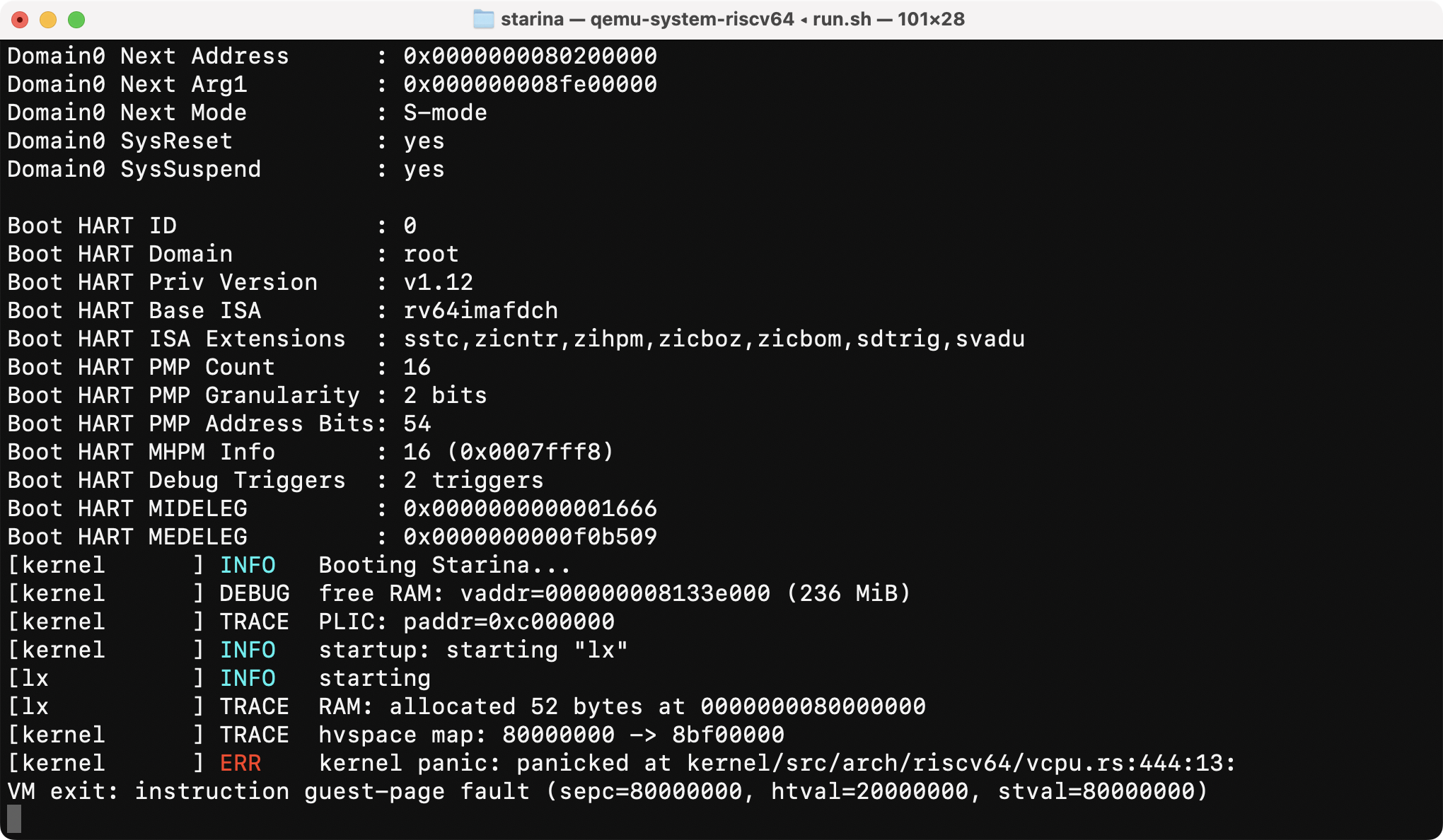
The kernel panicked with an interesting error name: instruction guest-page fault. Yes, CPU has entered the guest mode!
Step 2: First ecall
The next step is to run something in the guest mode. Let’s start with a simple ecall:
const BOOT_CODE: &[u8] = &[
0x73, 0x00, 0x00, 0x00, // ecall
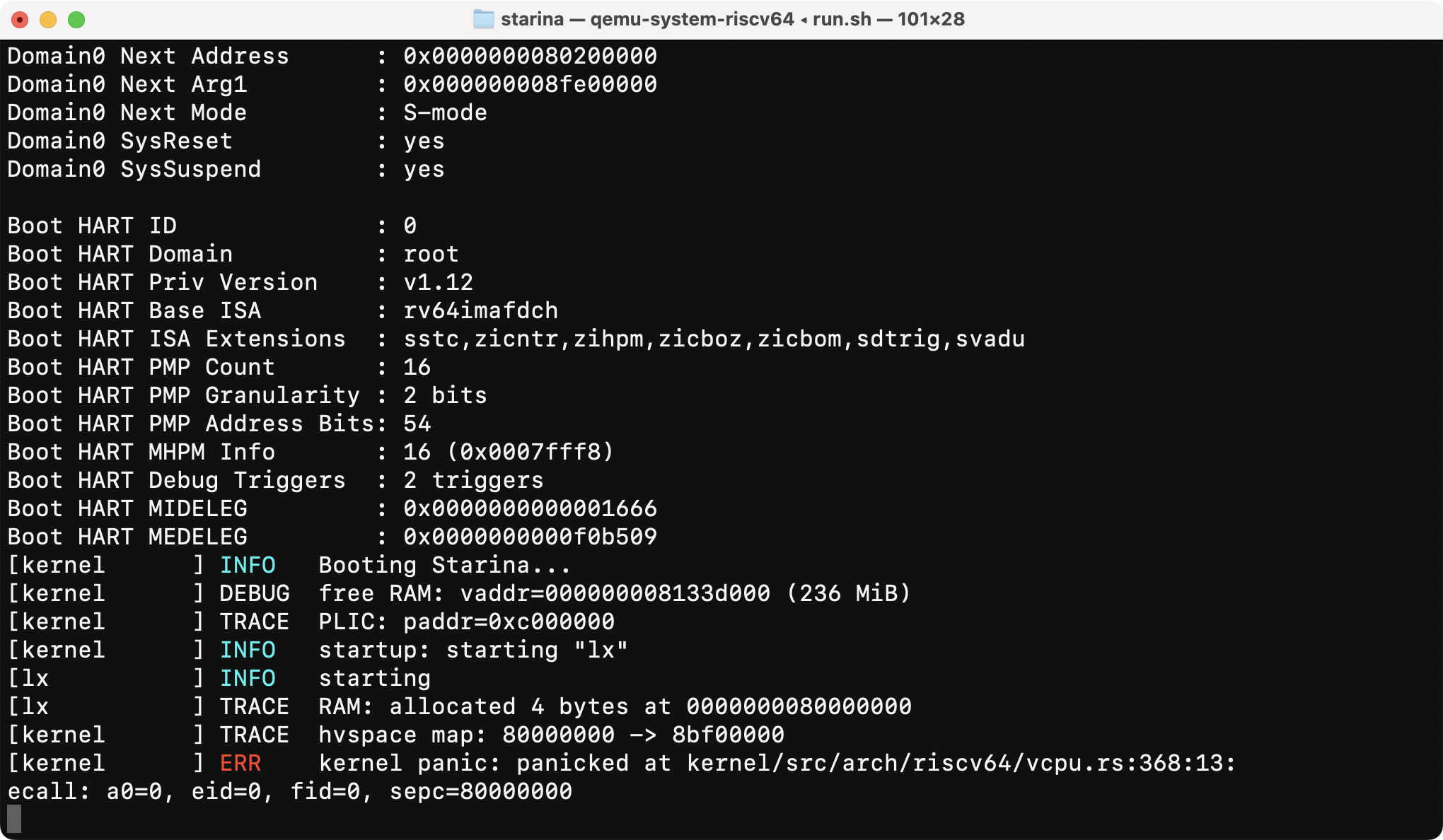
];To make it work, we need to prepare the guest’s page table which maps the guest-physical address to the host-physical address so that the CPU can read the instructions in BOOT_CODE.
RISC-V defines another paging modes called Sv39x4/Sv48x4/Sv57x4, and they’re mostly identical to Sv39/Sv48/Sv57. The only caveat is U bit needs to be set to 1 for kernel pages too.
Once hgatp is set, I got another trap reason:
Step 3: Hello World from guest!
Now we’re ready to run a Hello World program. I wrote a simple program in assembly:
.section .text
.global _start
_start:
li a0, 'H'
li a7, 1
ecall
li a0, 'i'
li a7, 1
ecall
li a0, '!'
li a7, 1
ecall
li a0, '\n'
li a7, 1
ecall
unimp
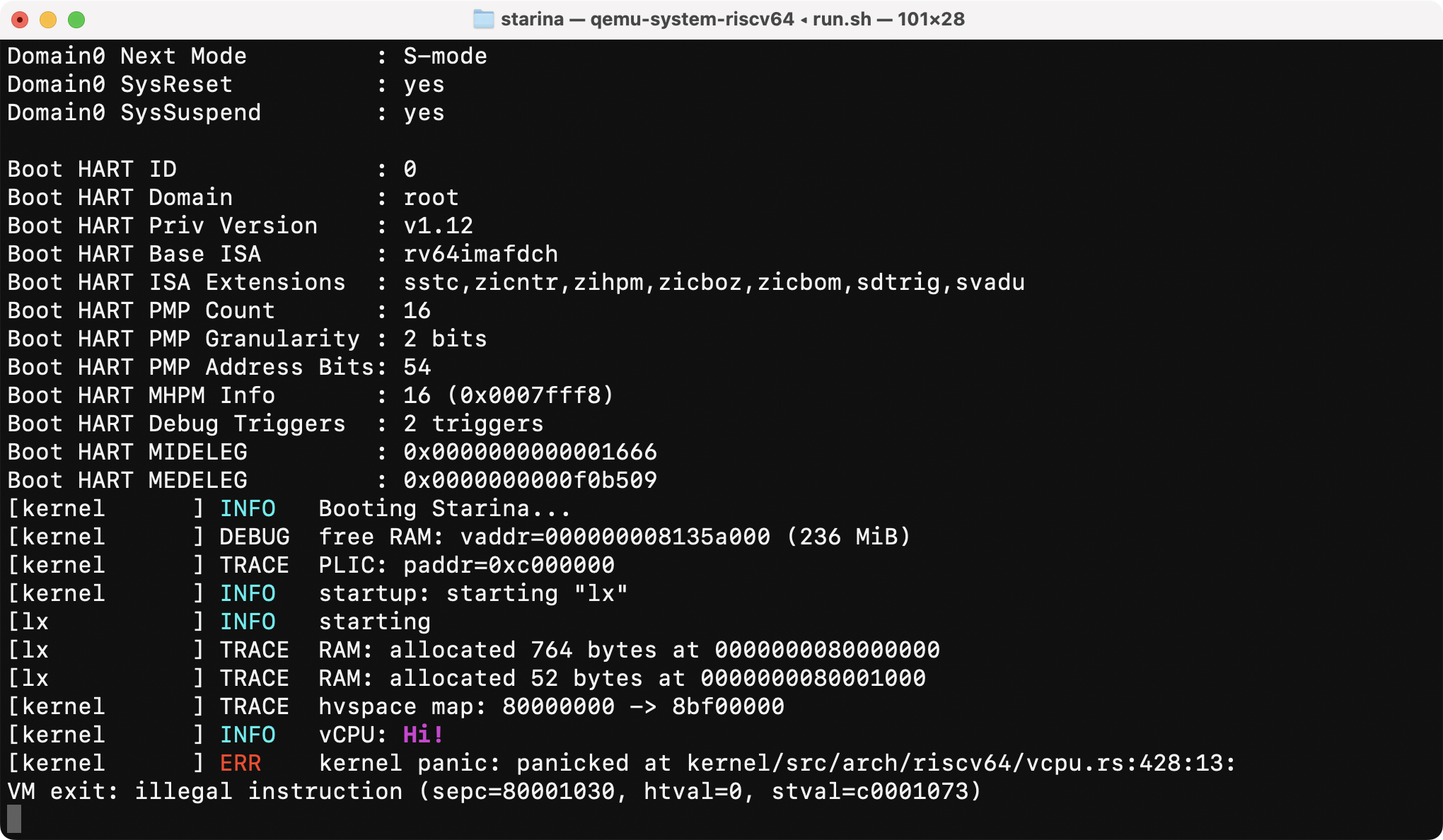
This assumes hypervisor’s ecall handler implements the SBI, a RISC-V’s BIOS interface. This snippet calls so-called putchar API and finally calls an invalid instruction (unimp) to trigger a trap.
Building this tiny guest OS is easy:
$ clang --target=riscv64 -march=rv64g -nostdlib -Wl,-Ttext=0x80200000 guest.S -o guest.elf
$ llvm-objcopy -O binary guest.elf guest.bin
And it works!
Step 4: Booting Linux
Our minimal guest Hello World worked, so it’s time to try with Linux.
Here are some kernel config options I enabled:
CONFIG_SERIAL_EARLYCON_RISCV_SBI=y
CONFIG_RISCV_SBI_V01=y
CONFIG_HVC_RISCV_SBI=y
CONFIG_RISCV_TIMER=y
Linux kernel for RISC-V can be built with:
make ARCH=riscv CROSS_COMPILE=riscv64-linux-gnu- Image
The boot image format is documented here, and it’s basically raw binary. Just copy the image file into the guest memory, and jump to the beginning when the CPU enters the guest mode.
Looks like Linux booted, but it crashed with a null dereference:
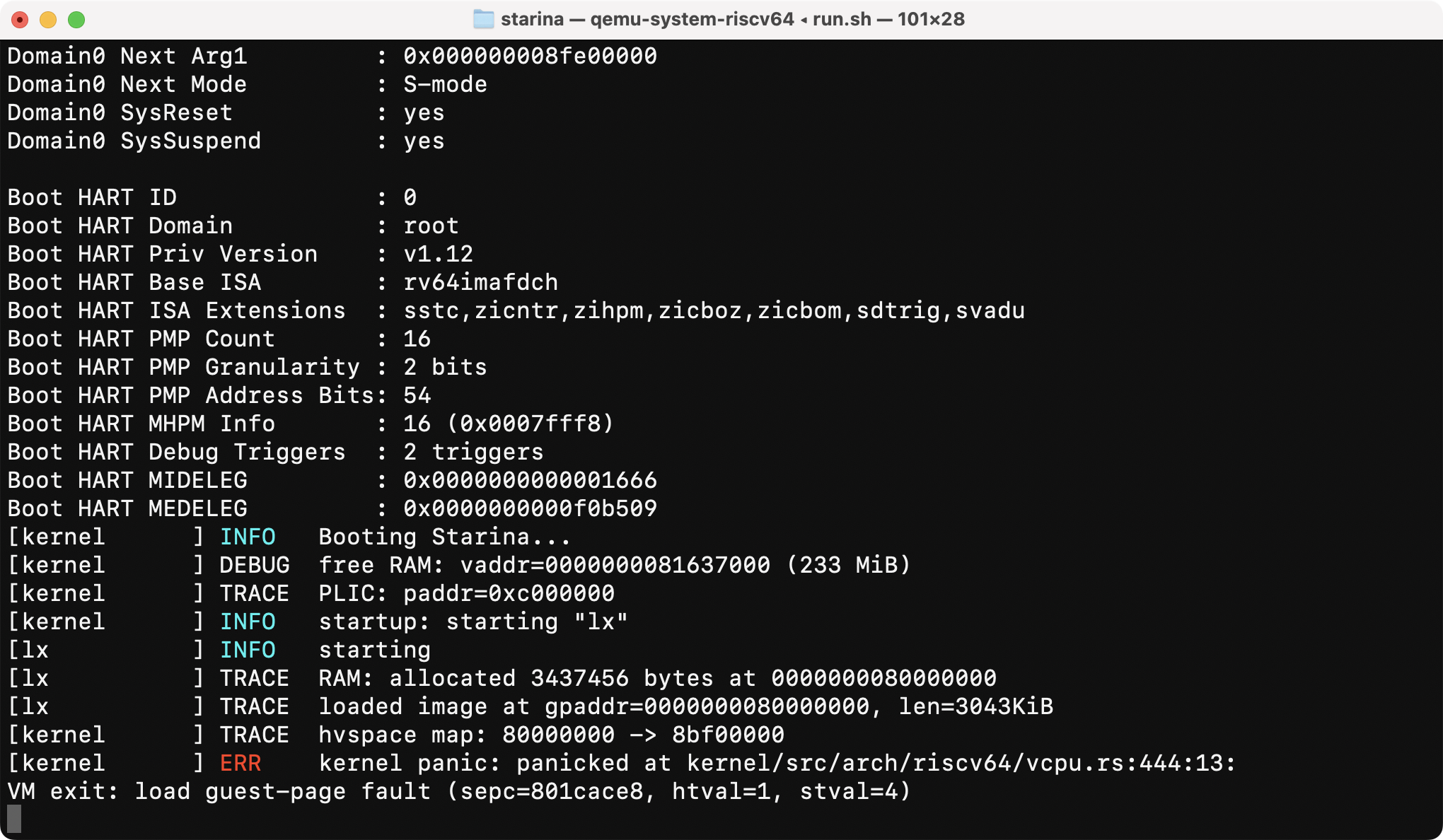
According to the sepc value, the kernel panicked at __pi_fdt32_ld:
$ gobjdump -d linux/vmlinux | grep -A 5 801cace8 | head
ffffffff801cace8 <__pi_fdt32_ld>:
ffffffff801cace8: 00054783 lbu a5,0(a0) <-- null deferecence here!
ffffffff801cacec: 00154703 lbu a4,1(a0)
ffffffff801cacf0: 0187979b slliw a5,a5,0x18
Step 5: Device Tree
In RISC-V, we need to provide a device tree, a tree data structure defining what devices are available in the computer.
Fortunately, we can use a Rust crate for this: vm-fdt, a device tree builder from RustVMM project (famous for Firecracker). The library supports no_std, so it was super easy to use it in Starina (thank you, thank you RustVMM folks!).
To make Linux work, the device tree should include at least: free memory areas (reg in device_type = memory), and CPUs with RISC-V ISA extensions (riscv,isa-extensions).
Step 6: rdtime support
After adding the device tree, I got another trap. Looks like Linux tried to read rdtime but failed because hcounteren was not set:
hcounteren register is clear, attempts to read the cycle, time, instret, or hpmcounter n register while V=1 will cause a virtual-instruction exception
The fix is to fill hcounteren CSR. Easy peasy.
Step 7: Timer support
While booting, Linux kernel tries to probe the abilities of the CPU and peripherals. That intialization step is mostly done by itself without any help from the hypervisor. However, there’s a bit head-scratching part: the timer speed detection.
In the step, Linux kernel waits for jiffies to progress and it looks as if it’s hanging if the hypervisor doesn’t implement timer.
In RISC-V there are two approaches to implement a timer:
sbi_set_timer: Call the hypervisor (SBI) to set the timer.sstcextension: A CPU extension to trigger a timer interrupt without hypervisor’s help.
This step is also the first time I needed to inject interrupts into the guest. While RISC-V spec is clean, but I was totally lost with how to do it. Setting hideleg was what I needed to do, but I was confused by RISC-V Advanced Interrupt Architecture, which extends the RISC-V interrupt handling.
RISC-V extensions are more sometimes look like “patches” to the base spec. RISC-V Unified Database is a great resource to understand how the extensions extend the base spec.
Once I enabled sstc extension and implemented interrupt handling correctly, the kernel booted successfully:
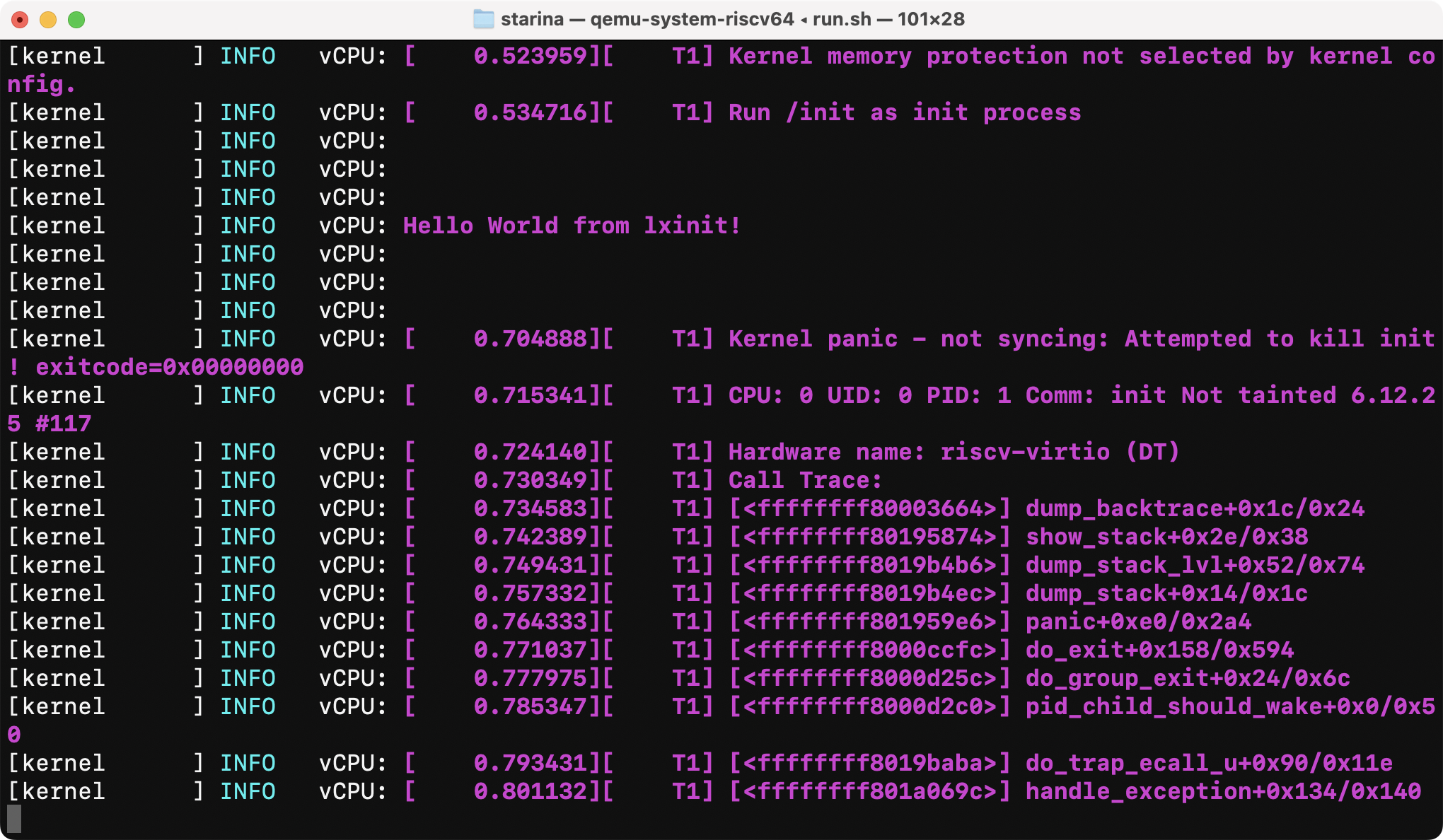
Step 8: MMIO support
Linux booted successfully on Starina’s hypervisor. The next step is to provide devices. In RISC-V, as in other architectures, devices are mapped to physical addresses (memory-mapped I/O). Devices need to be emulated are:
- An interrupt controller. The guest kernel needs it to read pending interrupts, and acknowledge them. PLIC in RISC-V.
- Disk device: Where the root filesystem is stored. Virtio-blk is a popular choice.
- Network device: For networking. Virtio-net is the most popular choice.
In hypervisor, MMIO is implemented by not mapping anything at the address range. That is, everytime the guest tries to access the address range:
- The CPU tries to read/write a MMIO address, but it’s not mapped. Trigger a guest page fault.
- The hypervisor checks if the address range is a MMIO address.
- Decode the instruction to determine destination/source registers, and the access width.
- Emulate the MMIO operation.
- If it’s a read, write the value to the register.
- Advance the program counter to the next instruction, and resume the guest.
Doesn’t it sound a bit hacky? In MMIO, hypervisor behaves like a CPU interpreter. Fortunately, RISC-V is very simple and gives us summary of the instruction in htinst CSR. In x86-64, … good luck!
For future RISC-V hypervisor developers, here are few pitfalls I encountered:
- A guest physical address written to
htvalis shifted right by 2 bits. You’ll see a weird address if you forget this. htinstcould be compressed instruction. This means the instruction width is not always 4 bytes, but sometimes 2 bytes.
Step 9: virtio-fs
This is the last step of this post. While virito-blk is a typical choise to provide the root filesystem, I chose something different: virtio-fs.
Why? Because it allows more seamless integration with Starina. I plan to write another post about the integration, but in short, Starina provides some virtual files to the guest.
Virtio-fs is a virtual filesystem over Virtio. More specifically, it uses FUSE (Filesystem in Userspace) protocol to communicate with the guest kernel.
I have nothing to say about this step because we’ve finished the hypervisor-specific steps already! Design a good virtio library, implement the virtio-fs emulation on top of it, and you’re done:
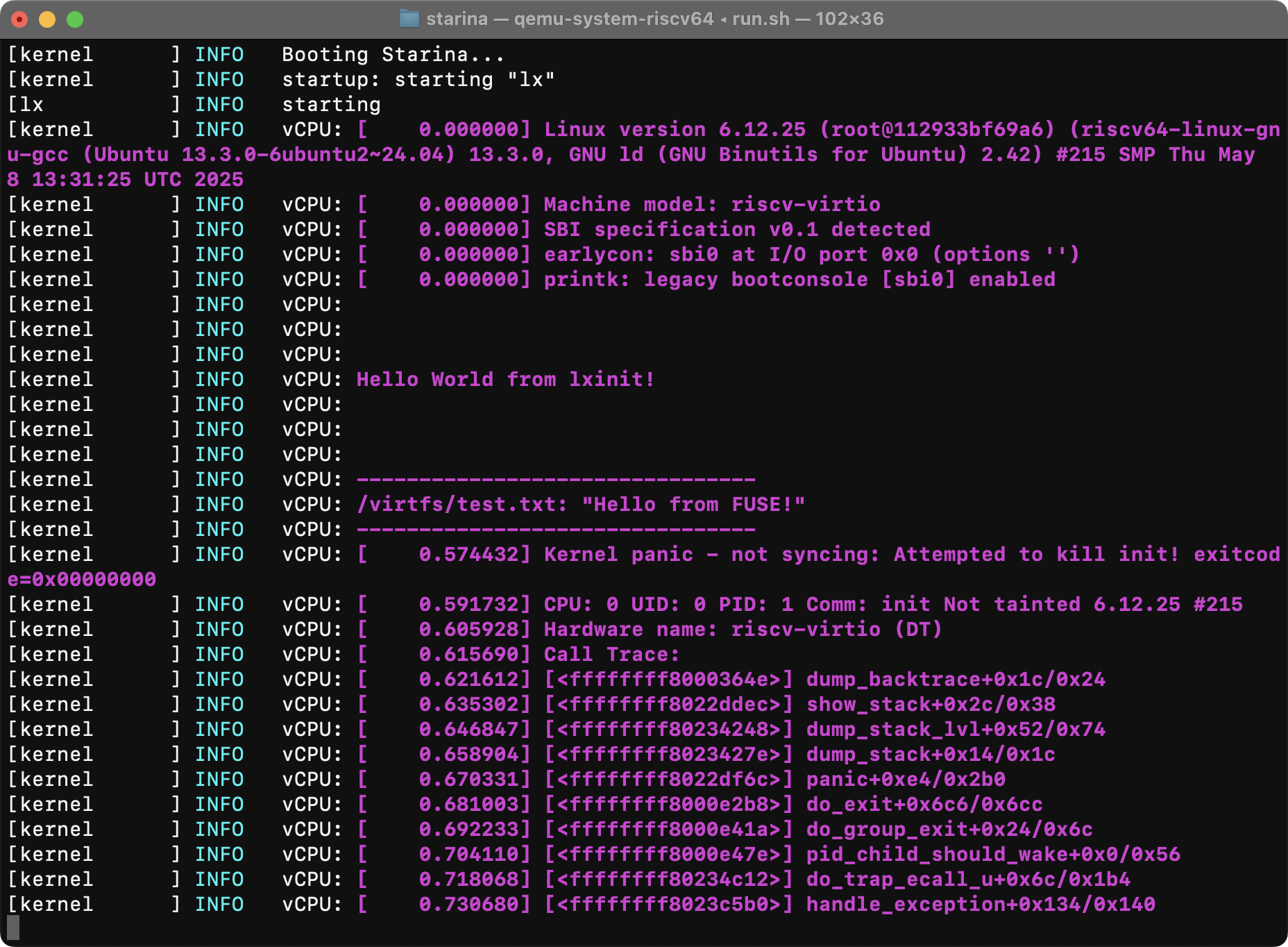
Phew, that’s it!
Tip: Debugging both hypervisor/guest worlds
Starina supports Unikernel-like mode, where the microkernel and apps are built into a single ELF executable. This is not only for performance, but also for debugging.
Here’s a gdbinit script which enabled me to watch VMM, hypervisor in Starina kernel, and the Linux kernel in guest:
# Load Starina (hypervisor's) debug info
file build/kernel/debug/kernel
# Load Linux (guest's) debug info
add-symbol-file path/to/vmlinux
And look! You’re seeing the guest’s kernel stack trace!
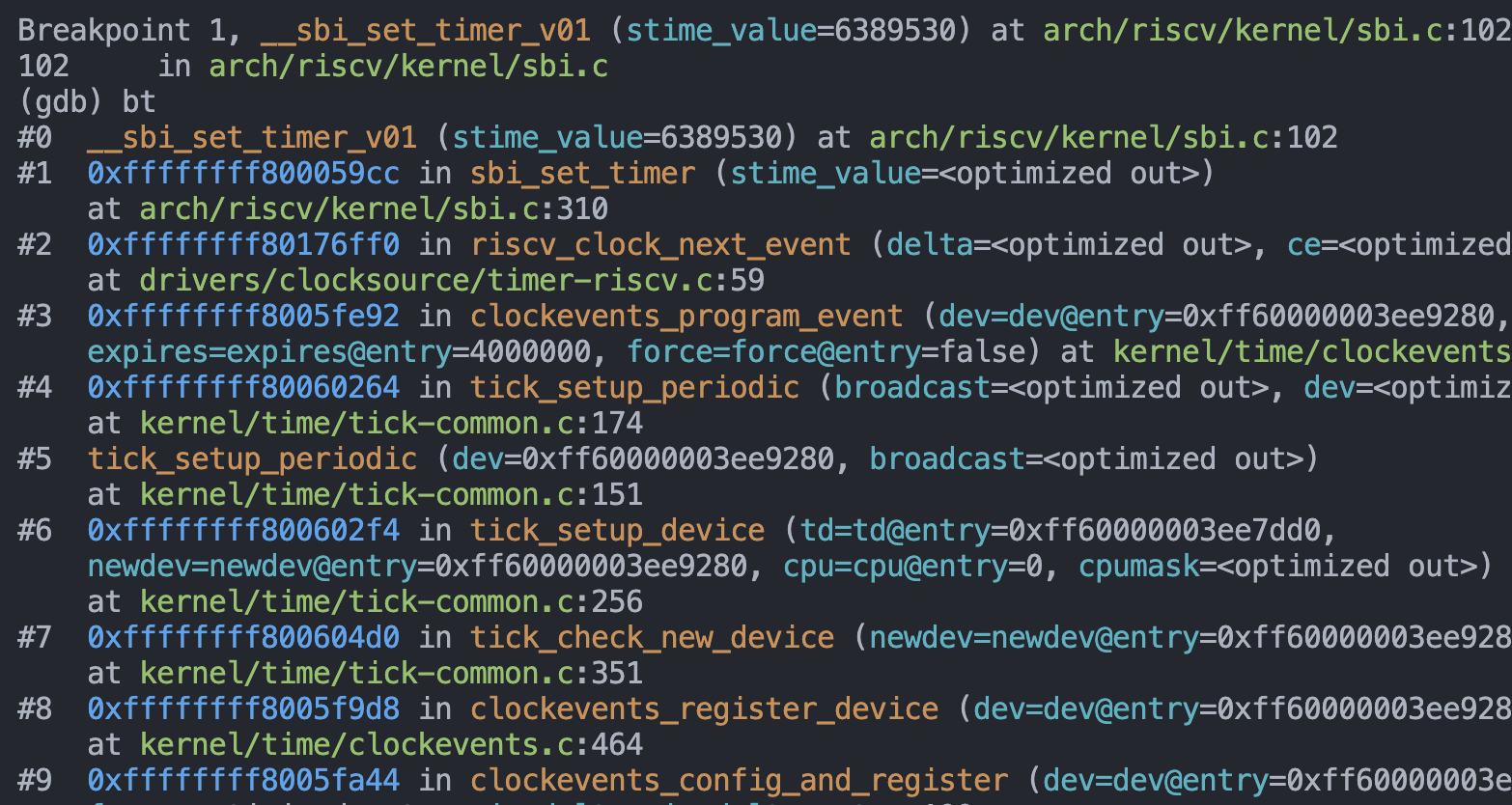
This is why I haven’t yet implemented stack traces in Starina: you just need to attach the GDB and type bt.